La méthode pour optimiser le référencement naturel de document PDF pour améliorer leur visibilité sur internet est semblable à l’optimisation « on page » d’une page HTML. Voici une liste de quelques points à respecter pour favoriser l’indexation et le bon positionnement de vos fichiers PDF en ligne.
Optimisation SEO du texte du document PDF : contenu et structure.
Comme pour les pages HTML d’un site internet, le contenu texte d’un document PDF est fondamental pour obtenir un bon référencement. Il convient donc de rédiger un texte pertinent, original, de qualité et qui contient les mots clés de votre stratégie référencement naturel.
La quantité de texte scannée par les robots des moteurs de recherche est inconnue mais il est logique de penser que le début du document est plus important que les pages suivantes. N’hésitez pas à vous inspirer du modèle de la pyramide inversée utilisée en rédaction web.
Cela veut dire que la première page commence par un titre qui résume tout le document et un paragraphe d’introduction (chapô) qui développe ce titre et dévoile un peu plus le contenu qui va suivre. Le reste des contenus textes sera habilement structuré avec des intertitres, des listes à puces, etc.
Ce n’est pas tout de travailler le fond, pensez également à la forme. Evitez un texte disposé en trois colonnes dès la première page… Rien ne garantit que le robot soit capable d’interpréter cette disposition et de comprendre qu’il doit analyser le début de la première colonne uniquement…
Optimisation du nom du fichier PDF
Les noms de fichiers sont lus par les moteurs alors pensez à insérer des mots clés dans le nom de fichier de votre document PDF. Ecrivez par exemple catalogue-formations-referencement-naturel.pdf plutôt que catalogue2013.pdf !
Dans l’exemple ci-dessous, le nom de fichier est pour le moins obscur.

Utilisation des métadonnées du document PDF pour le référencement naturel.
Ces métadonnées sont similaires aux balises META d’une page HTML. Elles correspondent aux propriétés du documents et sont éditables avec le logiciel de création du PDF.
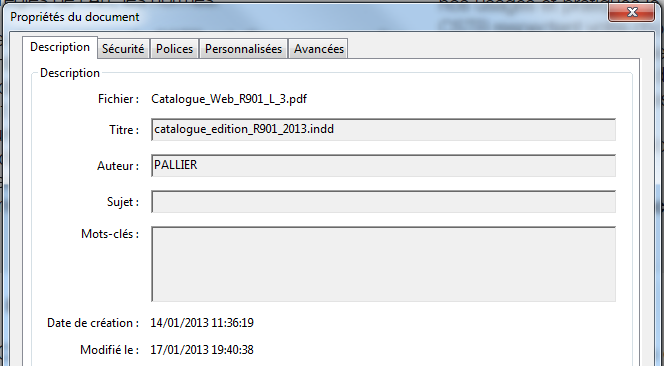
- Remplissez le Titre du document de la même façon que vous remplissez une balise Title de page web. Ce titre est lu et analysé par Google. Quant à Bing, c’est plus aléatoire.
- Pour les mots clés, c’est l’inverse. Le robot de Bing lit et analyse ces données mais pas celui de Google. Notre conseil : remplir ce champs sans fraude ni tromperie sur la marchandise. C’est-à-dire que vous indiquez un ou deux mots clés correspondant réellement au contenu du document mais inutile de mettre une liste de cinquante mots clés !
- Quant au champ «Auteur » et «Sujet », rien n’indique qu’ils soient utilisés par les moteurs actuellement mais leur remplissage ne nuit pas à l’indexation et au référencement naturel du document.
Optimisation de la taille du document.
Pensez à réduire le poids du fichier pour améliorer l’expérience utilisateur de l’internaute qui télécharge le document.
S’il s’agit du catalogue général des produits de votre entreprise, découpez-le par gammes de produits. Cela réduira le poids du document et vous donnera l’opportunité d’intégrer les mots clés de la gamme dans le nom de fichier et le titre du document.
Optimisation des hyperliens qui pointent vers le document PDF.
Lorsque vous créez des liens vers vos documents PDF, décrivez le contenu du PDF en utilisant des mots clés pertinents.
A ne pas faire :
Pour télécharger le catalogue de nos formations au référencement naturel, cliquez-ici
A faire :
Téléchargez notre catalogue de formations au référencement naturel
Le risque du contenu dupliqué
La mise en ligne de documents PDF sur un site internet comporte parfois le risque de duplicate content, c’est-à-dire de contenus rigoureusement identiques ou fortement similaires à ceux des pages HTML du site.
Plusieurs solutions sont alors possibles et dépendent des situations :
- empêcher l’indexation du document PDF en utilisant une ligne X-Robots-Tag :noindex dans l’entête HTTP.
- indiquer la version canonique (originale) dans le fichier sitemap.xml du site ou utiliser la balise « link rel canonical » dans la version HTML.
Sur ce dernier point, n’hésitez pas à consulter les sites :
www.abondance.com d’Olivier Andrieu
www.webrankinfo.com d’Olivier Duffez